
12: Practical Applications, Part II: Miscellaneous
-
POKELLMON: A Human-Parity Agent for Pokemon Battles with Large Language Models
Are Transformers Effective for Time Series Forecasting? (May 2022)
ChatAug: Leveraging ChatGPT for Text Data Augmentation (Feb 2023)
Using GPT-4 to measure the passage of time in fiction (Mar 2023)
ChemCrow: Augmenting large-language models with chemistry tools (May 2023, added 5/16/23)
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
Exploiting Novel GPT-4 APIs
(Dec 2023, link)
The paper tests how three novel OpenAI APIs can be maliciously exploited. They find:
Fine-tuning GPT-4 can remove its safety features. For example, it is quite straightforward to fine-tune on a malicious dataset that will introduce bias to GPT-4’s answers about a political person.
The OpenAI function calls get executed without any kind of sanity check. So it is simple to do SQL injection into the parameters of a function call. That just means that the destination of the function call needs to guard against that (like any publicly available API).
If documents retrieved in document retrieval contain malicious instructions, the LLM will follow those. For example, a document could contain statements introducing bias on a political person, and GPT-4 will parrot that.
POKELLMON: A Human-Parity Agent for Pokemon Battles with Large Language Models
(Feb 2024, link)
Neat paper which uses an LLM to fight Pokemon battles: it turns the state and history of a battle into text, then asks the LLM which action to generate next. The paper has all kinds of detail about how to turn battle states into text descriptions. Here is the overall LLM performance. It’s really not that great! GPT-4 is way better than Llama-2.

But here is an interesting table that looks at the efficacy of different prompting methodologies, which is a nice practical application of these: CoT is chain-of-thought, SC is self-consistency (generate 3 options and have the LLM vote on them), ToT is tree-of-thought. Interesting to see that SC goes to 64% from CoT at 54%. And overall, performance goes way up vs. just the simplest prompt.

Here is the performance of knowledge-augmented generation: the LLM is getting access to a dictionary of Pokemon that injects knowledge on attacks into the prompt.

Two other observations:
POKELLMON tends to take actions that can achieve short-term benefits, therefore, making it vulnerable to human players’ attrition strategy that requires long-term effort to break.
Experienced human players can misdirect the agent to bad actions.
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence (Jun 2023, added 6/13/23)
(link)
The paper tests how well various GPT models work to create answers to tax problems. It is a straightforward but rigorous setup - and it has some great insights into the real-world application of GPT. The authors generate multiple-choice problems, each consisting of a question and a set of potential answers (only one of which is correct). The facts, names and numbers for each problem are randomly generated by Python code. So these are problems that cannot directly be in the LLM training corpus.
They test the models in various different ways:
bypass_retrieval: Simply provide the LLM with a multiple choice question and the answer options with no additional explicitly provided legal context
similarity_search: Inject potentially relevant legal text into the prompt, using the open-source Facebook AI Similarity Search library to create and search embeddings of tax code documents; the four best-matching documents (by cosine similarity) are provided in the prompt
gold_truth: Directly provide in the prompt the correct source material (which they have from having generated the question in the first place)
lecture_notes: Provide context to the LLM in the form of lecture notes relevant to the given question type
mega_run: Combines the gold_truth retrieval method, use few-shot prompting, and chain-of-thought prompting of GPT-4.
Here is the chart that matters - accuracy for various combinations of retrieval/prompting methods and GPT models:
Insights:
Not surprisingly, GPT-4 is way better than the other models, though GPT-3.5 comes quite close
As we know by now, smaller models do not get better with tricks like chain-of-thought - they just get more confused/overwhelmed
Incredibly fascinatingly, giving more context in similarity_search has no performance improvement! In other words, adding tax code documents to the prompt didn’t make much of a difference. However, adding the exact right tax documents to the prompt does make a meaningful difference.
The best performance is GPT-4 with 40-60% accuracy, which is ok but not great. However, that’s very likely held back by the fact that tax problems often require math, and surely the model gets that wrong too often (though the paper doesn’t study that).
Are Transformers Effective for Time Series Forecasting? (May 2022)
(link)
It would seem like transformers should be great at time series forecasting, because the big upgrade that transformers enabled over, say, recurrent neural networks is the attention mechanism: it can make full use of the entirety of a time series. However, that actually isn’t true:
Self-attention is permutation-invariant and “anti-order” to some extent. While using various types of positional encoding techniques can preserve some ordering information, it is still inevitable to have temporal information loss after applying self-attention on top of them. This is usually not a serious concern for semantic-rich applications such as NLP, e.g., the semantic meaning of a sentence is largely preserved even if we reorder some words in it.
However, when analyzing time series data, there is usually a lack of semantics in the numerical data itself, and we are mainly interested in modeling the temporal changes among a continuous set of points. That is, the order itself plays the most crucial role.
The paper challenges Transformer-based LTSF solutions with direct multi-step (DMS) forecasting strategies to validate their real performance.
We introduce a set of embarrassingly simple models named LTSF-Linear as a new baseline for comparison. LTSF-Linear regresses historical time series with a one-layer linear model to forecast future time series directly.
LTSF-Linear outperforms existing complex Transformer-based models in all cases, and often by a large margin (20-50%).
In contrast to the claims in existing Transformers, most of them fail to extract temporal relations from long sequences, i.e., the forecasting errors are not reduced (sometimes even increased) with the increase of look-back window sizes
This is an overview of transformer solutions for LTSF:

Some notes:
The self-attention layer in the Transformer architecture cannot preserve the positional information of the time series. However, local positional information, i.e. the ordering of time series, is important. Besides, global temporal information, such as hierarchical timestamps (week, month, year) and agnostic timestamps (holidays and events), is also informative. To enhance the temporal context of time-series inputs, a practical design in the SOTA Transformer-based methods is injecting several embeddings, like a fixed positional encoding, a channel projection embedding, and learnable temporal embeddings into the input sequence. Moreover, temporal embeddings with a temporal convolution layer or learnable timestamps are introduced.
This simple model is the linear forecasting model that they deploy and which performs better than all transformers:
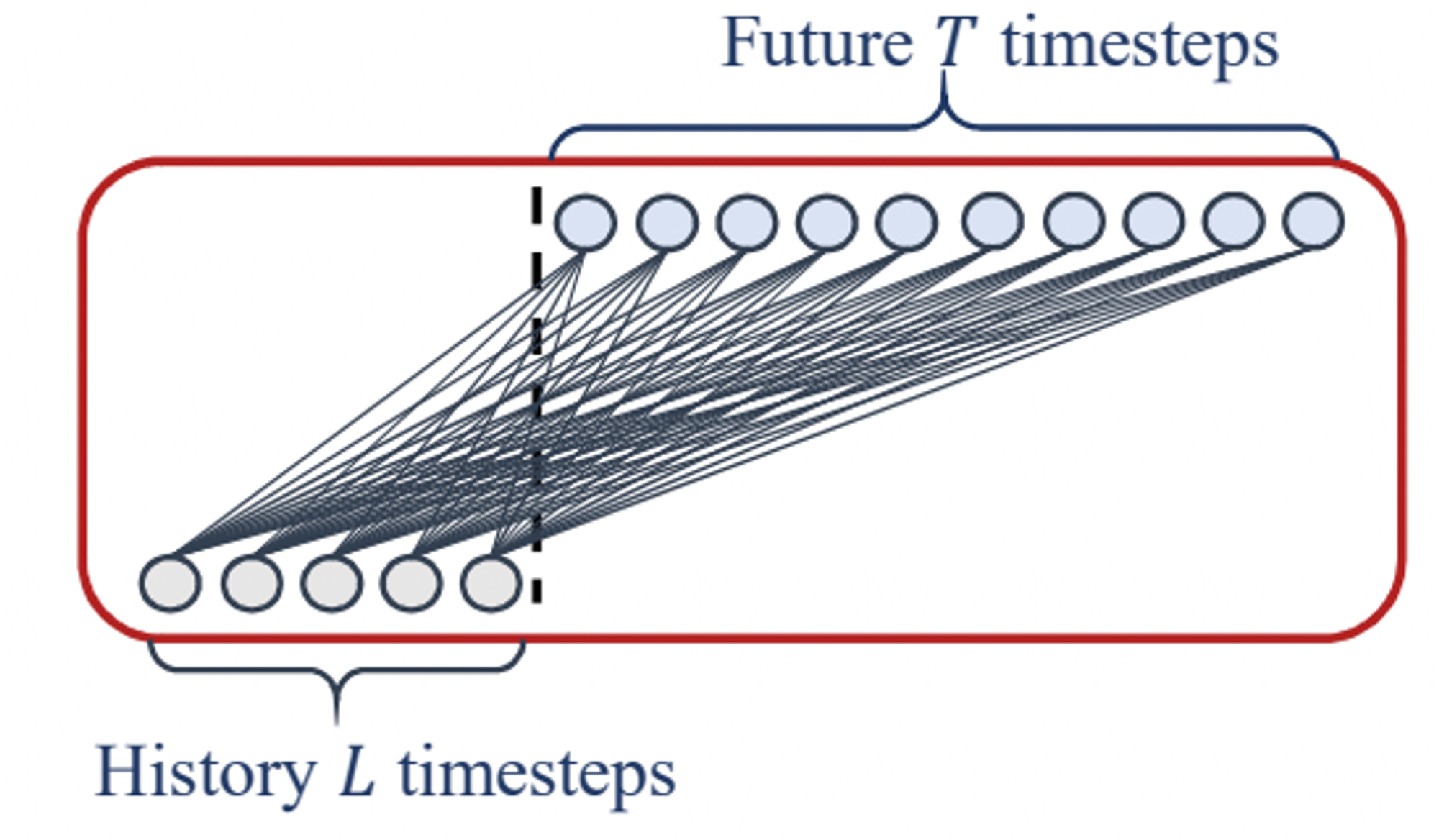
Here is an interesting problem: We argue that even with positional and temporal embeddings, existing Transformer-based methods still suffer from temporal information loss. We shuffle the raw input before the embedding strategies. Two shuffling strategies are presented: Shuf. randomly shuffles the whole input sequences and Half-Ex. exchanges the first half of the input sequence with the second half. Interestingly, compared with the original setting (Ori.) on the Exchange Rate, the performance of all Transformer-based methods does not fluctuate even when the input sequence is randomly shuffled. By contrary, the performance of LTSF-Linear is damaged significantly. These indicate that LTSF-Transformers with different positional and temporal embeddings preserve quite limited temporal relations and are prone to overfit on noisy financial data, while the LTSF-Linear can model the order naturally and avoid overfitting with fewer parameters.
(However, in my view: one of the time series they forecast is an exchange rate. It might just be silly to try to do that based on just previous exchange rate data. So maybe this whole paper is less about the power of transformers and more about the stupidity of trying to forecast time series based on their own past.)
ChatAug: Leveraging ChatGPT for Text Data Augmentation (Feb 2023)
(link)
Simple idea: if you only have a limited dataset on which to finetune a model, then use ChatGPT to turn those limited training examples into a larger number by simply re-writing them.
PRIMEQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development (Jan 2023)
(link)
The paper presents PRIMEQA: an open-source repository designed as an end-to-end toolkit, with all the necessary tools to easily and quickly create a custom QA application. This comes with example notebooks and code. The alternative to this appears to be LangChain.
This has 3 components:
Retriever: Retrievers predict documents (or passages) from a document collection that are relevant to an input question. We provide a single Python script run_ir.py that can be passed arguments to switch between different retriever algorithms.
Sparse: BM25 is one of the most popular sparse retrieval methods. Our Python-based implementation of BM25 is powered by the open-source library PySerini
Dense: We currently support ColBERT and DPR: both fine-tune pretrained language models to train question and passage encoders. They utilize FAISS for K-nearest neighbor clustering and compressed index representations, respectively, and support multilingual retrieval with the question and the documents being in the same or different languages.
Reader: Given a question and a retrieved passage—also called the context—a reader predicts an answer that is either extracted directly from the context or is generated based on it. PRIMEQA supports training and inference of both extractive and generative readers through a single Python script: run_mrc.py.
Extractive: PRIMEQA’s general extractive reader is a pointer network that predicts the start and end of the answer span from the input context. It can be initialized with most large pre-trained language models. In addition, our reader is extremely versatile as it can provide responses to questions with list answers, yes/no responses to Boolean questions, answer spans found in tables and in multimodal (text+image) documents.
Generative: PRIMEQA provides generative readers based on the popular Fusion-in-Decoder (FiD) algorithm. Currently, it supports easy initialization with large pre-trained sequence-to-sequence (henceforth, seq2seq) models. With FiD, the question and the retrieved passages are used to generate relatively long and complex multisentence answers providing support for long form question answering tasks, e.g., ELI5.
Question generator: Question generators take a span of text (e.g., a sentence) from a document as input, hypothesize an answer (e.g., a named entity) and generate a question as output.
Unstructured Input: Our first variant of QG is a multilingual text-to-text model capable of generating questions in the language of the input passage. It fine-tunes a pre-trained T5 language model on publicly available multilingual QA data
Structured Input: We also provide QG capability over tables, for which the generator is trained on examples of SQL and natural language question pairs extracted from the popular Table QA dataset. During inference, PRIMEQA uses a controllable SQL sampler to select SQL queries for a given table and answer text, and then applies the trained QG model to generate natural language questions.
Using GPT-4 to measure the passage of time in fiction (Mar 2023)
Simple idea: ask GPT-4 to measure the passage of time per page that is implied in the narrative of a novel. The author previously did that before manually with a few readers, and their inter-reader reliability is 0.74. So GPT-4 almost gets there.

ChemCrow: Augmenting large-language models with chemistry tools (May 2023, added 5/16/23)
One question to me is, can you use the mysterious inference mechanism of LLMs to solve problems that more traditional machine-learning algorithms can’t crack? It sounded like this paper might try that. But no, what this really is is just an example for auto-formalization, in the chemistry realm: the paper teaches an LLM to use various chemistry tools, to pull information into the LLM’s context window from those tools, and to then do the usual text inference on all that information, using chain-of-thought. Turns out it’s quite good at it. This is essentially the same workflow as in the Toolformer and the ReAct papers (and various other ones listed in this document). They’re using GPT-4 and prompting to set up the tool-enhanced LLM (no fine-tuning). Here are the tools that the LLM can “call”:

An example for a prompt: “I need to synthesize a sample of atorvastatin. Please tell me how to synthesize it. Then tell me how much it will cost to buy all the reactants I need.” Here is the performance, comparing to plain (unenhanced) GPT-4:

It’s a really simple paper, but a good example for how much tool-enhanced GPT-4 can do in a particular niche area.
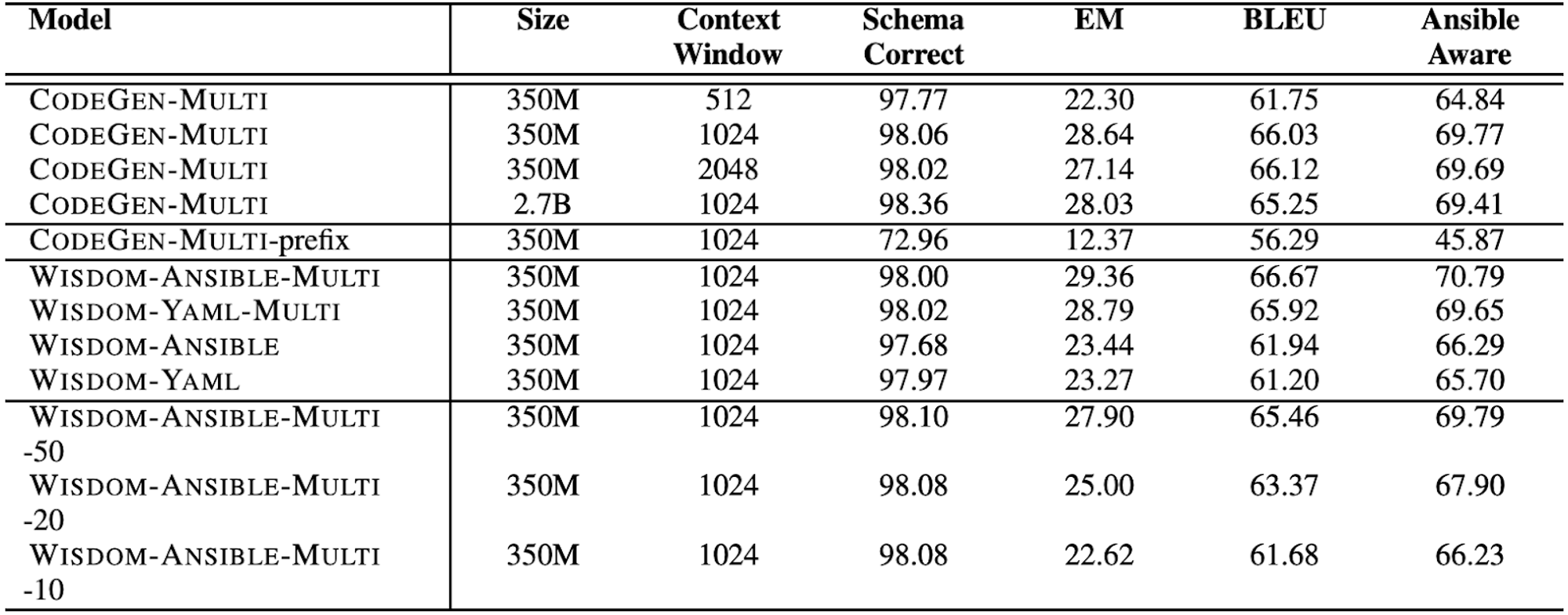
Automated Code generation for Information Technology Tasks in YAML through Large Language Models (May 2023, added 5/17/23)
This is a useful paper to understand fine-tuning of code generation LLMs on a specific, exotic programming language. In other words, how much better do code generation LLMs get in a particular language “niche” when further trained on examples in that language? This paper trains an LLM to produce Ansible YAML files: these are YAML (a type of configuration file) files for setting up and managing IT infrastructure.
First, the paper starts with the Salesforce code generation model called CodeGen. It then uses two new datasets constructed in the paper with YAML files to train new models: (1) it trains Wisdom-Ansible and -Yaml only on those YAML file datasets, and (2) it starts with the CodeGen checkpoints (which already have all the other Pile and BigQuery pre-training) and further pre-trains them on those YAML file datasets.

Here is some nice benchmarking in terms of dataset size for additional pre-training: the paper uses the GitLab and GitHub YAML files it collected for pre-training (PT) for the table above. (The Galaxy dataset is used for fine-tuning, FT, see below.) For comparison: (1) The Pile has 350 billion tokens of natural language and 31 billion tokens of code; (2) BigQuery has around 119 billion tokens of code in 6 programming languages; (3) BigPython has around 71 billion tokens of Python code. CodeGen has seen a large amount of natural language, but only a limited number of Ansible-YAML. For example, the Pile only includes around 25K Ansible-YAML and 600K generic YAML files. Now, when the paper trains Wisdom-Yaml-Multi, it uses the table below, which is another 1.1 billion training tokens, specifically for YAML. So I’d say that’s about 4x more than the YAML that CodeGen had already seen in its base training.

Finally, the paper also does further fine-tuning: it uses the Galaxy dataset, which contains full Ansible “playbooks” (those are apparently the types of YAML files you’d use to configure your IT).
The results are quite remarkable: the table below shows performance on various benchmarks (which I don’t know, but whatever) for the different models. These are all few-shot results, so you’re using the 2K context window to give some Ansible-YAML examples, and then the model gets going. The results are quite a bit better for the YAML-trained models.

Even better, here are the results for further fine-tuned models. So these models are all fine-tuned on that Galaxy dataset mentioned above (well-designed Ansible-YAML playbook files). Here, you can dispense with few-shot prompting and just ask the model which task to solve, and it will produce, and the performance scores are even better.
Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(Mar 2024, link)
Here is a great chart with data from Spotify. The first chart first creates co-listening graphs: when at least one user listens to two particular podcasts, those two podcasts get linked (they were co-listened); same for audiobooks. Chart c) show that such co-listened audiobooks have higher similarity in their content embeddings. These embeddings are simply embeddings of the title and description of the audiobook. Chart d) shows the similarity between two audiobooks that were not directly co-listened to, but each was co-listened to with one podcast. (So user Amy listened to audiobook 1 and podcast x, and user Bob listened to audiobook 2 and also podcast x.) Again, their content embeddings are more similar than random.

This is good evidence that textual descriptions of items do matter to express practical, personal tastes.