
02: Steering: How To Control LLMs
-
Chain of Hindsight Aligns Language Models with Feedback (Mar 2023)
Natural Language Decomposition and Interpretation of Complex Utterances (May 2023, added 5/23/23)
UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation (Mar 2023)
The Power of Scale for Parameter-Efficient Prompt Tuning (Sep 2021)
Boosted Prompt Ensembles for Large Language Models (Apr 2023)
Text Classification via Large Language Models (May 2023, added 5/18/23)
Prompt Engineering - A Survey (Mar 2023)
This is the best overall overview article of all methods related to inferencing with LLMs. Hits on everything from chain-of-thought prompting to the Toolformer paper (using external APIs) to producing Python code to answer a question.
Chain of Hindsight Aligns Language Models with Feedback (Mar 2023)
(link)
Paper proposes a novel technique, Chain of Hindsight, that is easy to optimize and can learn from any form of feedback. We convert all types of feedback into sentences, which are then used to fine-tune the model, allowing us to take advantage of the language comprehension capabilities of language models.
Simple idea: generate 4 outputs A, B, C, D for a particular question from an LLM.
A human rater ranks the 4 outputs and tells the model that: “A is better than B, which is about as good as C, and both are better than D”.
This data is then used as a “chain of hindsight” for reinforcement learning with the LLM.
The results look better than without “chain of hindsight” training: left the results on ROUGE, right the results on a dialog dataset.
Natural Language Decomposition and Interpretation of Complex Utterances (May 2023, added 5/23/23)
(link)
Simple idea: if you want to write a program and you have a complex prompt, decompose it into elementary prompts, and those will be easier to write and re-compose. Here are some examples: listed at the top are the “elementary utterances” - the indivisible steps that you’re decomposing everything else into. In the bottom left, you have complex utterances - you want to decompose those into the elementary ones.
How do you do that? Best through an iterative approach:
Natural language decomposition: given the original prompt, and all code fragments produced to date, and all elementary steps you’ve found so far, find the next elementary step.
Program generation: given the original prompt, and all code fragments produced to date, and all the elementary steps you’ve found so far, and the elementary step you just found in step 1, write more code.
Then interleave steps 1 and 2 until the problem is solved.
You can fit all this into two simple prompts. In each prompt, give a bunch of examples of previous decompositions, and that’s it.
UPRISE: Universal Prompt Retrieval for Improving Zero-Shot Evaluation (Mar 2023)
(link)
The chart below shows the idea: train a small language model that is able to map a task description into the prompt for a big LLM that will best guide the LLM to solve the task. So the small LM becomes the prompt retriever, and the retrieved prompt will then be run through the LLM.

The prompt retriever is a bi-encoder model where the input encoder EX(·) takes the task input xi as input, and the prompt encoder EP (·) takes prompt pj as input.
Then the retriever is trained to maximize the similarity score between the task input and the corresponding prompt input.
After fine-tuning the prompt encoder, we use it to encode the entire prompt pool with EP (·).
At inference time, for a testing input instruction xtest, we compute its encoding EX(xtest) and then use maximum inner-product search over the prompt pool to retrieve K most similar prompts, sorted by their inner product in descending order, denoted as P+ = (p1, ..., pK). We then concatenate the prompts with the task input, resulting in the concatenation pK ⊕ ... ⊕ p1 ⊕ xtest.
This prompt then gets fed into the LLM.
The Power of Scale for Parameter-Efficient Prompt Tuning (Sep 2021)
(link)
The paper introduces “prompt tuning,” a simple yet effective mechanism for learning “soft prompts” to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signals from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3’s few-shot learning by a large margin.
Also interesting: prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method “closes the gap” and matches the strong performance of model tuning (where all model weights are tuned)
This is a cool chart that shows this: prompt tuning gets to the same score performance as full-scale model tuning (and way better than picking the right textual prompt).

How does it work?
When an LLM gets a prompt, the n tokens in the prompt first get converted into an embedding of dimension e. So that, as always, becomes a matrix of dimension (nxe) - i.e., a vector of dimension e for each input prompt token n.
Now, the soft prompt is simply another matrix of p vectors of dimension e. That matrix is simply concatenated to the input prompt embedding matrix. All of that then flows through the model as normal.
To initialize the (p,e) matrix: conceptually, our soft-prompt modulates the frozen network’s behavior in the same way as text preceding the input, so it follows that a word-like representation might serve as a good initialization spot.
Then you simply run a few training loops that minimize the error by only varying the parameters in the (p,e) matrix. That becomes your tuned soft prompt.
It’s crazy that even just appending one token already improves performance, particularly for larger models. But more trainable parameters in the soft prompt are better (though it stalls out around 20).

Boosted Prompt Ensembles for Large Language Models (Apr 2023)
Writing a good prompt for an LLM is powerful, but even more powerful is this: “prompt ensembling” - the method uses a small dataset to construct a set of few-shot prompts, each of which progressively solves more of the problem. The final output of the algorithm is
an accumulated set of LLM prompts with representation throughout the difficult parts of the problem space. This works on around 100 labeled training examples.
Here is how their algorithm works:
Say you have a situation where you have lots of questions or tasks of similar nature. You want to write the absolute best possible few-shot prompt that when you put any question into it, it will solve it. (Few shot = a prompt where you give several examples.) LLM performance is really sensitive to how you write a prompt, so this really matters.
Start with a prompt for which you (hand-)select a few questions for which you have the correct answers. That becomes your initial prompt.
Then run a few questions through the LLM using that prompt, using chain-of-thought (meaning, the LLM has to explain itself along the way). In fact, run each question several times, and count how often the LLM produces the correct answer for that question. (The answers for even the same question will differ because of the probabilistic nature of LLMs - the paper uses temperature = 0.7)
There will be some questions for which the LLM struggles more than for others. Those questions are “hard”, in some sense of the word - with your current prompt, the LLM just can’t solve them 100% of the time. But now find those questions for which the LLM has produced some correct answers - those are hard, but not impossible.
Take the reasoning paths from “hard” questions that led to correct answers. Now sort those reasoning paths by the number of sentences in them - the longer, the better!
Take a few of those long, correct reasoning paths for “hard” questions (not 100% correct all the time), and append them to the input prompt.
The intuition is that this new input prompt is better at covering the entire problem space because you “generalized” it with an example that it previously struggled with. Now go back to step 3 and run everything again with that new prompt. Keep adding to that prompt in the same way.
This seems to keep out a few more performance points on important datasets:

Other observations:
This works for bigger LLMS (like gpt-3.5), but it doesn’t do anything for worse ones.
You get a really neat intuition for what happens when you look at this in embeddings space: take the (question, answer)-tuples in the entire dataset you’re solving for, and show them in 2-dimensional embeddings space (meaning, anything that the model thinks is semantically similar will be closer together in this plot). Those are the faded dots in the plot below. Then do the same with the (question, answer)-tuples in your initial prompt. Those are the black stars below. Then run the above algorithm, where you’re adding more and more (question-answer)-tuples to the prompt. You can see that the new examples you’re including in your improving prompt will cover more and more of the “problem space”.

Learning to Compress Prompts with Gist Tokens (Apr 2023)
You can either (a) prompt a model or (b) fine-tune it. Prompting it takes valuable space in the LLM's context window, and fine-tuning for each prompt (== expected behavior) is too expensive. Instead, the paper proposes "gisting", which trains an LM to compress prompts into smaller sets of "gist" tokens which can be reused.
Gisting enables 26x compression of prompts, resulting in up to 40% FLOPs reductions, 4.2% wall time speedups, storage savings, and minimal loss in output quality.
This looks similar to prefix-tuning (where you train a different model to learn a sequence that you prepend to the LLM, and you know that that sequence will coax the right behavior out of your main LLM). For gisting, instead of training another, different model, you use the LLM itself to learn the compression: while doing standard instruction fine-tuning, you modify the transformer attention masks to enforce prompt compression. So gisting gets learned while fine-tuning, and thus incurs no additional training cost on top of standard instruction fine-tuning.
Here is the algorithm:
You're doing instruction-tuning. You have lots of pairs of (task, input, output) that you're running through the model for training, and you're training the model to produce (output) when it sees (task, input).
What you simply do during the training stage is to instead feed the model (task, <special gist token G1> <special gist token G2> input). The transformer is constantly training its "attention weights": it learns to put a weight on how each token in this sequence relates to each other token in the sequence.
For gisting, you force the transformer to NOT put any link between all the tokens coming AFTER the gisting tokens and the tokens BEFORE the gisting tokens. But you keep training it anyway. So the transformer has to learn to produce the correct output simply by seeing the gist tokens, because its weights won't have "access" to the task description tokens. See below for an illustration: the transformer is forced to not have any connection between the tokens “translate french” (the task tokens) and the tokens “the cat” (the input tokens). So it needs to deduce entirely from seeing <G1> and <G2> that the task is to translate french. It will “learn” to associate those tokens with “translate french”.

Observations:
Models were generally insensitive to the number of gist tokens k: compressing prompts into a single token did not substantially underperform more gist tokens. In fact, having too many gist tokens hurts performance in some cases (e.g. LLaMA-7B, 10 gist tokens), perhaps because the increased capacity enables overfitting to the training distribution. Use the single gist models for the rest of the experiments in the paper.
Crucially, we expect G to generalize to unseen tasks: given a new task t, we can predict and use the corresponding gist activations G(t) without any additional training.
Ensemble Refinement as a better prompting strategy for complex problem-solving (May 2023, added 5/18/23)
This is from the Google Med-PaLM 2 paper, and it is independent from the clinical domain of that paper. When you need an LLM to solve a complex problem (here: answering a medical question), then you can use the following strategies:
Few-shot prompting: give a few examples in the prompt for what good looks like
Chain-of-thought: ask the LLM to “show its work”, i.e., write down step by step how it is coming to its solution
Self-consistency: ask the LLM the same question several times (can even be with different temperature settings, i.e., put a higher probability on otherwise lower-probability answers), then have the LLM vote at the end on what is the best answer
Ensemble refinement: This is a new idea in the paper.
Ask the LLM the question using all of the above strategies. Repeat that several times, at different temperatures. Record all the answers.
Feed all the answers back into the LLM and ask it to refine the best answer.
Run that process multiple times. Record the best refined answer from each run.
Do a majority vote at the end through the LLM on which is the best answer.
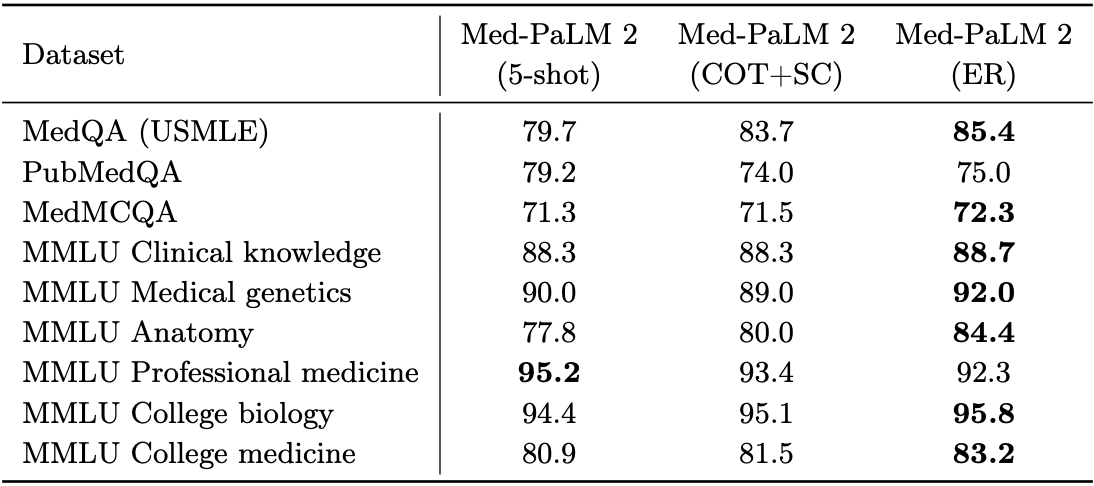
Here is how much impact this has: look at ER vs. COT+SC (chain-of-thought plus self-consistency). You get another 2-5 points in performance.
Text Classification via Large Language Models (May 2023, added 5/18/23)
Apparently, LLMs still underperform heavily fine-tuned models for text classification. (Generally you’d think LLMs are way better at that than any other model, because they have so much more contextual and world knowledge, but the paper has some examples for interesting LLM failures.) The paper straightforwardly comes up with a good idea for smarter prompt design for text classification tasks. Everything interesting is captured in the image below. The paper uses text-davinci-003 (obviously pretty outdated by now vs. GPT-4). That LLM doesn’t know what to do with a in the image below. Adding chain-of-thought (CoT) doesn’t help. But instructing the model to follow a particular strategy does work: first, find emotional clues, second, summarize. This is actually a similar idea to the ensemble refinement concept by Google. It’s an important tool in the toolkit.
